E-Smart MPC
AI制御 ー PID制御より賢く、強化学習より実用的
E-Smart MPC とは?
製造元:株式会社 Proxima Technology
制御盤の中からAI制御を実現
製造業の制御システムに革新をもたらす「E-Smart MPC (Edge・Embedded・Economical Smart MPC)」は、従来のPID制御の限界を突破し、 強化学習の実装課題を解決する画期的なAI制御コントローラーです。
産業用Raspberry Pi 5をベースとした堅牢なハードウェアに、弊社独自の Smart MPC® を搭載しています。
制御盤に収納可能なコンパクトサイズで、製造現場への導入を容易にしました。

E-Smart MPCのソフトウェアの構造
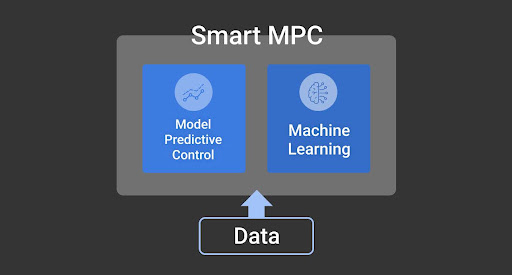
Smart MPC®は、モデル予測制御(Model Predictive Control)と機械学習(Machine Learning)を組み合わせた制御アルゴリズムです。
モデル予測制御の長所を引き継ぎつつ、その欠点であるモデリングの難しさを機械学習によるデータドリブンな方法で解決します。
この技術によって、データを取る環境さえ用意することが出来れば、導入コストが高いモデル予測制御を比較的簡単に運用可能になります。
アーキテクチャ
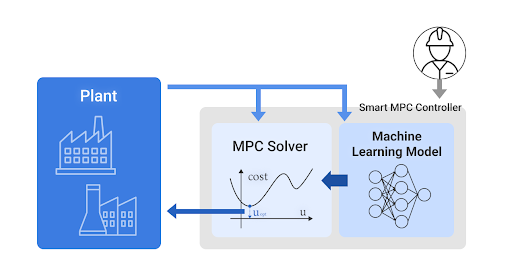
制御システムは制御対象(プラント等)と制御器の2つの要素から構成されています。
制御器の中にはプラントのダイナミクスを模倣するための機械学習モデルと、MPC(モデル予測制御)に用いるための数理最適化ソルバーが存在します。
機械学習で得られたモデルはMPCの計算に使われ、毎ステップ(例えば1秒ごと)に最適な制御入力を計算し、プラントに渡します。
E-Smart MPCのソフトウェアの特徴
強化学習との比較
Smart MPCはデータからモデルを構築・学習しながら、上記のMPCのアルゴリズムによって制御を行います。 一方でAlphaGoやDQNのような(モデルフリーの)強化学習には、モデルという概念が存在せず、ダイナミクスの学習と行動の決定はすべてQ関数に押し込められています。
本来、状態の価値がわかることと、未来が予測できるかどうかということは別問題であり、これらは分割して解くことが可能であると考えられます。 強化学習を難しくしている原因の一つが、この2つの異なる問題を一気に解こうとしているためであり、Smart MPCではこれらを個別に解くことで学習を著しく簡単かつ安定にすることが出来ました。
一方で、Smart MPCは評価関数は別個与えてやる必要があるため、評価関数が比較的自明に与えられる問題、例えば温度の乖離やエネルギーの消費量など、であれば適用可能ですが、それが不可能な問題、例えば囲碁や将棋など状態の評価自体が最も重要である問題に対しては直接的には使うことが出来ません。 Bonanzaメソッドのように過去のデータから逆最適化問題を解くことで評価関数を構成することは可能ですが、このタイプの問題には強化学習を使うことが最適であると思われます。
PID制御との比較
PID制御は現代において最も使われている制御手法であり、多くのプラントや機械の制御に使われています。 非常に単純なアルゴリズムであり挙動が理解しやすいため現場で作業者が調整を行いやすいというメリットがある一方で、以下ような欠点を持ちます。
・一入力一出力(SISO)系しか扱えない。
・拘束条件を扱えない。
・学習機能はなく、すべて人間が調整する。
・パラメータの調整は系統的に行うことは難しく、一般的に勘と経験に基づいて行われている。
・根本的にむだ時間に弱く、ハンチングやオーバーシュートを防ぐためにはスミス補償器のような補助的な機器を用いる必要がある。これはPIDの長所である理解のしやすさを損なわせるものである。
Smart MPCは上記すべての欠点を克服することが可能であり、一方でPID制御に決して劣らない手軽さやわかりやすさを備えています。
E-Smart MPCの活用先
製造現場が直面する制御の課題解決
製造現場の制御システムでは、従来方式では対応しきれない課題が明確になりつつあります。
1. PID制御の限界
・むだ時間(遅延)を含むプロセスで性能が低下
・多変数制御で相互干渉が発生し、不安定化しやすい
・非線形システムでは調整が困難
2. 制御調整にかかる負担
・1プロセスあたりの調整に長時間を要する
・最適化が熟練エンジニアの経験に依存
・環境変化のたびに再調整が必要
3. 先進制御導入のハードル
・強化学習は学習データと計算資源の確保が課題
・従来MPCは専用システムが高額で、専門知識も必要
・産業用PCやサーバーを設置するスペースの確保が困難
E-Smart MPCは、これらの課題を現場レベルで解消するために設計されています。
現場環境に最適化された次世代の制御アプローチとして活用いただけます。
Smart MPC®は、常に最新のデータに基づいて制御モデルをアップデートし続けるため、経年劣化や設備更新に伴う制御性能の低下にも柔軟に対応可能です。
従来は人手に頼っていた制御操作やチューニングも自動化され、安定した性能を維持しながら、運用負荷の軽減を実現します。
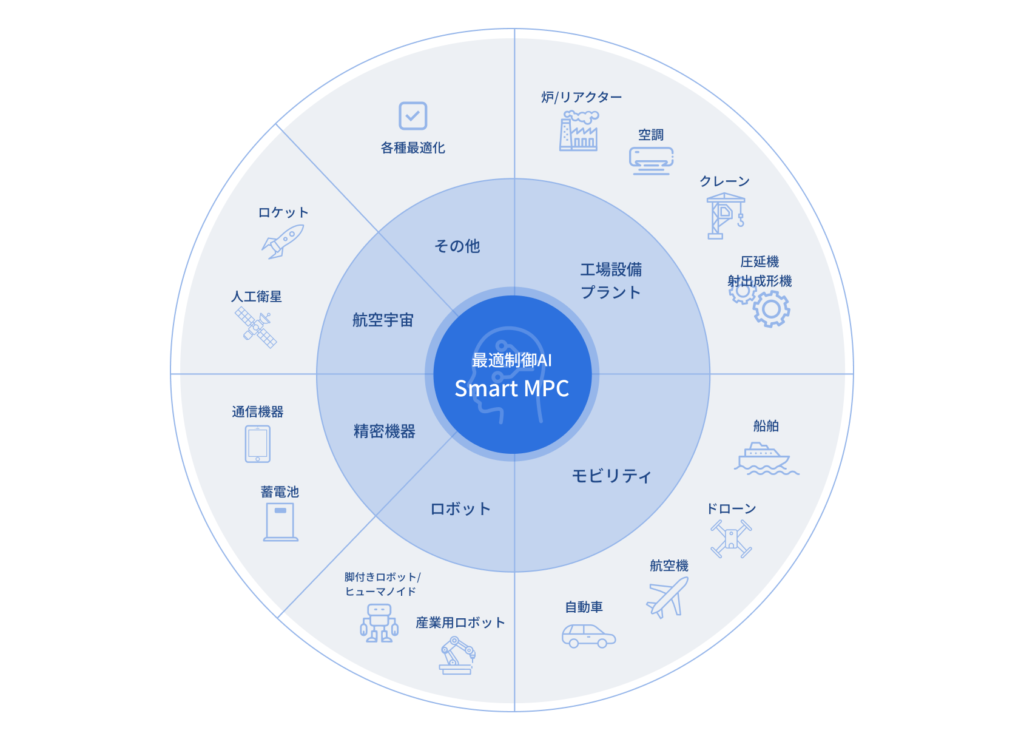
下図は、Smart MPC®がすでに活用されている、あるいは今後適用可能な領域を示した例です。工場設備やモビリティ、ロボット、航空宇宙といった幅広い分野・機器に対応可能です。
E-Smart MPCの製品仕様
ハードウェア仕様
・プロセッサ:Cortex A76(4コア)
・メモリ:8GB RAM
・ストレージ:eMMC 32GB+SSD 128GB~1TB
・筐体:制御盤収納対応(産業用規格準拠)
・電源:DC24V(産業標準)
・動作温度:-20〜60℃
・ネットワーク:Gigabit Ethernet × 2ポート
・通信プロトコル:MCプロトコル等 対応
ソフトウェア仕様
Smart MPCエンジン
・独自開発の高速MPC演算アルゴリズム
・リアルタイム学習・推論エンジン
・自動パラメータ調整機能
システム要件
・各社主要PLCに対応
・Grafana連携による可視化・入力が可能
導入例
Smart MPC®の導入
今回、トリニティ工業株式会社様の「T.E.G.A.」のコントローラーとして、弊社の最適制御AI Smart MPC®を新たに導入しました。
「Smart MPC®」と「T.E.G.A.」が融合した、全く新しい塗装プラント向け空調制御システムを共同開発することに成功しました。
Smart MPC®は機械学習とMPC(モデル予測制御)を組み合わせた技術で、MPCのモデリングの難しさをデータドリブン方法で解決します。
当技術はMPCの特性を引き継いでいて、以下のようなメリットがあります。
・多入力多出力(MIMO)系に対応可能
・むだ時間に強く、ハンチングを起こしにくい
・拘束条件を扱える
・エネルギーなどの最適化が可能
さらに、以下のような特徴があります:
・機械学習による自動モデリング
・少ないデータでも適用可能な実用性
・オンライン学習による環境変化への適応能力
これらが実機への適用可能性を高めています。
Smart MPC®による改善
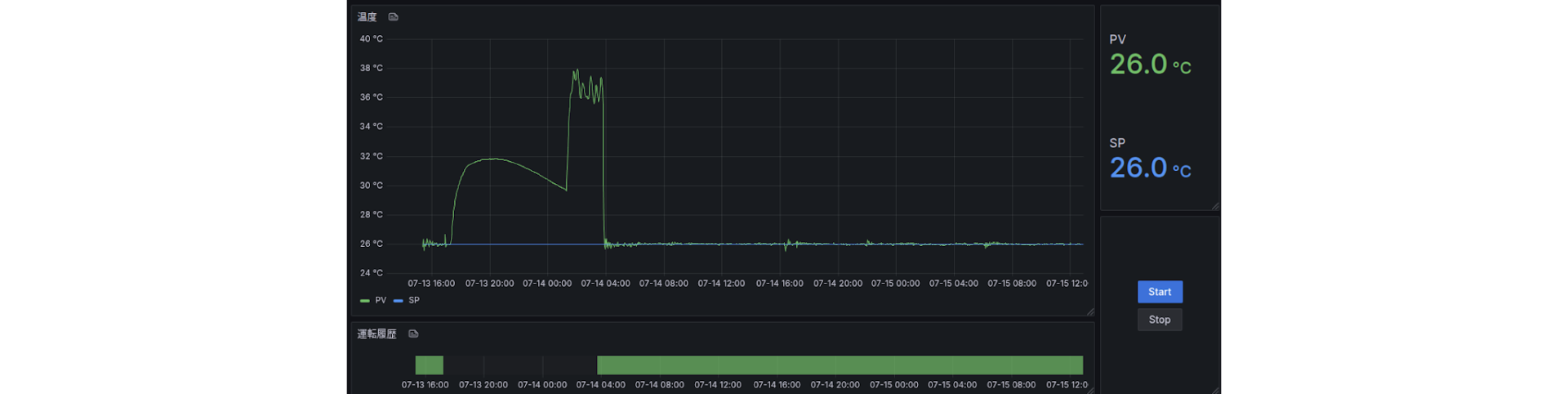
Smart MPC®による最適制御の動作については、空調とは異なりますが、炉の温度制御を模したデモの以下の動画で、御確認願います。
Smart MPC®の導入によって空調機の制御性能は以下のように改善しました:
・送気温度精度:±1℃ → ±0.2℃
・送気湿度精度:±5% → ±2%
・エネルギー消費量:5%削減(最大で年間300万円相当)
※空調機仕様、構成、稼働時間、原動力単価等により異なります。
まとめ
安定性の向上に加え、T.E.G.A.による省エネ制御にSmart MPC®の動的なエネルギー最適制御が加わることで、より大幅な省エネ化とCO2排出量の削減に成功しました。今後もさらなる性能向上を目指し、Smart MPC®の改良を継続してまいります。